Cơ bản

Data Science là gì? Biến dữ liệu thành insight có giá trị
Data Science không chỉ là câu chuyện của dữ liệu lớn hay thuật toán phức tạp. Ở Learning Chain, chúng mình nhìn khoa học…

AI cơ bản là kiến thức nền tảng về trí tuệ nhân tạo (Artificial Intelligence) mà bất kỳ ai muốn hiểu công nghệ hiện đại đều cần. Nếu bạn nghe về machine learning, ChatGPT, hoặc blockchain AI nhưng không biết bắt đầu từ đâu, đây là nơi bạn cần. Tôi sẽ chỉ bạn AI cơ bản thực sự là gì—từ lịch sử với Alan Turing và John McCarthy đến cách AI hoạt động trong đời sống hàng ngày. Không thuật ngữ rối rắm, không toán phức tạp—chỉ những gì bạn cần để hiểu trí tuệ nhân tạo như một người bình thường.

LLM là mô hình AI được huấn luyện trên lượng văn bản khổng lồ (hàng trăm tỷ token) để hiểu và tạo ra ngôn ngữ tự nhiên. Chúng không "hiểu" theo nghĩa con người, nhưng chúng học được các pattern ngôn ngữ cực kỳ phức tạp, cho phép tạo ra văn bản, trả lời câu hỏi, tóm tắt và giải thích với chất lượng gần như người thật.
Token ở đây có thể là một từ, một phần của từ hoặc ký tự. Hàng trăm tỷ token tương đương với việc mô hình “đọc” gần như toàn bộ internet công khai, sách, tài liệu, diễn đàn và nhiều nguồn dữ liệu khác. Điều quan trọng không phải là chúng ghi nhớ từng câu, mà là học được cấu trúc xác suất của ngôn ngữ — từ đó có thể tạo ra câu trả lời hợp lý trong ngữ cảnh mới.
Nói cách khác, LLM là một cỗ máy dự đoán cực kỳ mạnh mẽ — nhưng được tối ưu hóa để dự đoán ngôn ngữ.
 LLM học qua cơ chế self-supervised learning[/caption]
LLM học qua cơ chế self-supervised learning[/caption]
LLM học qua cơ chế self-supervised learning — dự đoán từ tiếp theo trong câu (next-token prediction). Qua hàng nghìn tỷ lần dự đoán, mô hình nội hóa ngữ pháp, ngữ nghĩa, logic và kiến thức thế giới. Sau đó, RLHF (Reinforcement Learning from Human Feedback) được dùng để tinh chỉnh hành vi theo mong muốn con người.
Cụ thể, quá trình huấn luyện thường gồm 3 giai đoạn:
Pre-training — Huấn luyện trên dữ liệu cực lớn để học cấu trúc ngôn ngữ chung.
Instruction tuning — Dạy mô hình cách trả lời theo dạng hướng dẫn.
RLHF — Con người đánh giá câu trả lời, từ đó điều chỉnh để mô hình phản hồi “hữu ích, an toàn, tự nhiên” hơn.
Điểm thú vị là LLM không được “dạy kiến thức” theo kiểu học thuộc lòng. Chúng xây dựng một không gian biểu diễn (embedding space) nơi các khái niệm liên quan nằm gần nhau. Vì vậy, khi bạn hỏi một câu mới, mô hình tìm trong không gian xác suất đó một câu trả lời phù hợp nhất.
OpenAI's GPT-4 dẫn đầu về khả năng tạo nội dung đa dạng. Anthropic's Claude nổi tiếng về độ an toàn và phân tích dài. Google's Gemini mạnh về tích hợp đa phương thức (text + image). Meta's Llama là model mã nguồn mở cho phép fine-tune tùy chỉnh — lý tưởng cho EdTech startup muốn xây sản phẩm riêng.
Ngoài ra, xu hướng hiện nay còn bao gồm:
Open-weight models cho phép doanh nghiệp tự triển khai on-premise.
Small language models (SLM) tối ưu chi phí inference.
Multimodal models xử lý văn bản, hình ảnh, âm thanh cùng lúc — mở ra khả năng AI chấm bài viết tay, phân tích biểu đồ, hoặc hỗ trợ học STEM.
Trong bối cảnh EdTech, việc lựa chọn model không chỉ phụ thuộc vào độ mạnh, mà còn phụ thuộc vào chi phí, khả năng tùy chỉnh và mức độ kiểm soát dữ liệu.
Tìm hiểu thêm:
LLM đang được dùng để:
(1) xây dựng AI Tutor cá nhân hóa,
(2) tự động chấm và phản hồi bài viết,
(3) tạo câu hỏi ôn tập từ giáo trình,
(4) dịch thuật nội dung đa ngôn ngữ,
(5) phân tích câu trả lời sinh viên phát hiện misconception, và
(6) generate lời giải thích thay thế khi học viên không hiểu.
Mở rộng hơn, LLM còn có thể:
Tạo lộ trình học tập thích ứng theo trình độ từng người.
Mô phỏng đối thoại Socratic để kích thích tư duy phản biện.
Chuyển nội dung sách giáo khoa thành flashcard, quiz hoặc game hóa.
Phân tích dữ liệu tương tác học tập để dự đoán nguy cơ bỏ học.
Hỗ trợ giáo viên thiết kế giáo án nhanh hơn.
Một AI Tutor tốt không chỉ trả lời câu hỏi — mà còn biết đặt câu hỏi ngược lại để giúp người học suy nghĩ sâu hơn. Đây chính là nơi LLM thể hiện sức mạnh vượt trội so với chatbot truyền thống.
Trước đây, cá nhân hóa là điều xa xỉ vì phụ thuộc vào giáo viên. Với LLM, mỗi học viên có thể có một “trợ lý học tập riêng” 24/7.
AI có thể:
Nhận diện học viên đang yếu ở khái niệm nào.
Điều chỉnh độ khó của câu hỏi.
Giải thích theo nhiều phong cách khác nhau (ngắn gọn, ví dụ thực tế, hình tượng, logic toán học…).
Điều này tạo ra một mô hình mới gọi là mass personalization — cá nhân hóa ở quy mô hàng triệu người dùng.
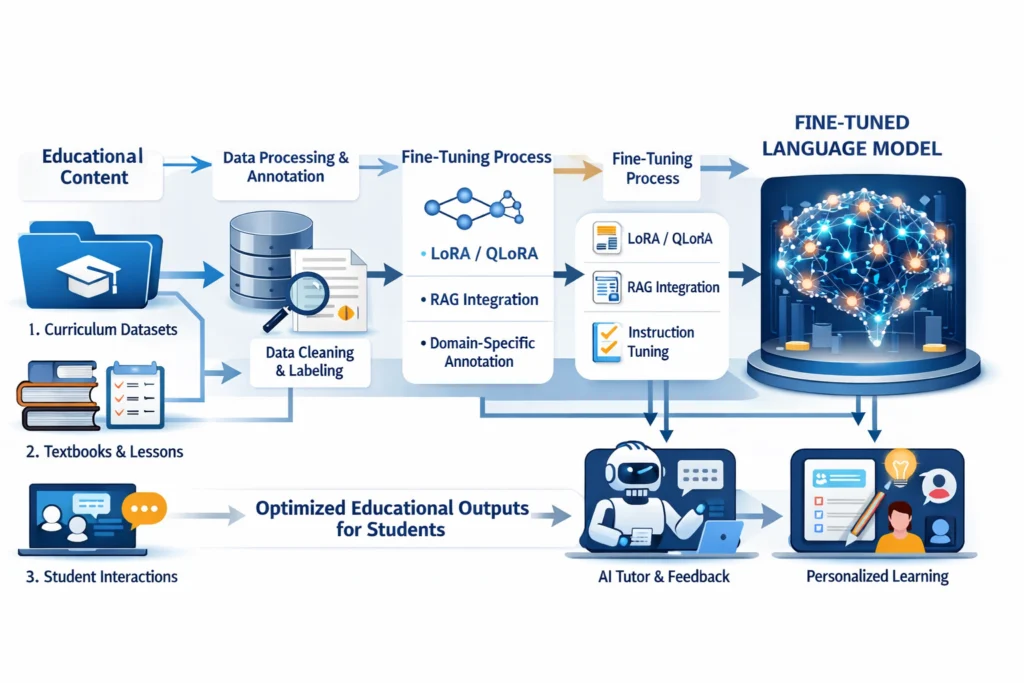
 Fine-tuning LLM cho giáo dục[/caption]
Fine-tuning LLM cho giáo dục[/caption]
Fine-tuning cho phép chuyên biệt hóa LLM cho một domain cụ thể. Một EdTech về Toán có thể fine-tune Llama trên dataset bài giải Toán, tạo ra AI Tutor Toán tốt hơn ChatGPT tổng quát. LoRA, QLoRA là các kỹ thuật fine-tune hiệu quả, giảm chi phí tính toán đáng kể.
Ngoài fine-tune truyền thống, còn có:
RAG (Retrieval-Augmented Generation) — kết hợp LLM với cơ sở dữ liệu riêng để đảm bảo thông tin chính xác.
Prompt engineering nâng cao — thiết kế cấu trúc câu hỏi tối ưu để hướng dẫn mô hình.
Instruction datasets chuyên ngành — tạo bộ dữ liệu nội bộ theo chương trình học.
Với EdTech startup, chiến lược thông minh không phải là xây model từ đầu, mà là tận dụng foundation model và tối ưu hóa theo niche market của mình.
Một hệ thống LLM trong giáo dục thường gồm:
Frontend app/web cho học viên.
Backend API kết nối model.
Layer RAG truy xuất giáo trình chuẩn.
Monitoring system để kiểm soát nội dung sai lệch.
Feedback loop để cải thiện chất lượng trả lời.
Việc kiểm soát chi phí inference (chi phí mỗi lượt hỏi đáp) cũng là yếu tố sống còn nếu sản phẩm có hàng nghìn người dùng đồng thời.
LLM có thể "hallucinate" — tạo ra thông tin sai nhưng trình bày tự tin. Trong giáo dục, điều này đặc biệt nguy hiểm. Cần có lớp fact-checking, RAG (Retrieval-Augmented Generation) và human review để đảm bảo độ chính xác. Theo dõi Learning Chain trên TikTok để cập nhật các best practice mới nhất.
Ngoài hallucination, còn có các rủi ro khác:
Bias dữ liệu — phản ánh định kiến từ dữ liệu huấn luyện.
Over-reliance — học viên phụ thuộc quá mức vào AI.
Data privacy — bảo mật thông tin người học.
Academic integrity — nguy cơ gian lận khi làm bài.
Vì vậy, LLM nên được xem là công cụ hỗ trợ — không thay thế hoàn toàn vai trò giáo viên.
Trong 5–10 năm tới, LLM có thể:
Trở thành lớp hạ tầng mặc định trong mọi LMS.
Kết hợp với VR/AR tạo lớp học mô phỏng.
Phân tích giọng nói và cảm xúc để điều chỉnh phương pháp dạy.
Tự động cập nhật giáo trình theo thay đổi của thế giới thực.
Giáo dục sẽ chuyển từ mô hình “một nội dung cho tất cả” sang “một nội dung cho từng người”.
LLM không chỉ là công cụ — mà là chất xúc tác cho một hệ sinh thái học tập thông minh, linh hoạt và mở rộng toàn cầu.
Cuộc cách mạng AI trong EdTech mới chỉ bắt đầu. Những ai hiểu rõ Large Language Model là gì và biết cách ứng dụng đúng sẽ tạo ra lợi thế cạnh tranh vượt trội trong thập kỷ tới.

Data Science không chỉ là câu chuyện của dữ liệu lớn hay thuật toán phức tạp. Ở Learning Chain, chúng mình nhìn khoa học…

Một trong những bước tiến lớn của AI gần đây là khả năng hiểu nhiều loại dữ liệu cùng lúc. AI đa phương thức…

Chắc bạn cũng từng bất ngờ ít nhất một lần: Face ID vừa liếc là mở khóa, TikTok vừa lướt đã gặp đúng video…

Bạn có bao giờ thắc mắc làm thế nào để nhóm các dữ liệu tương tự lại với nhau mà không cần phải gán…

Thuật toán thực chất là gì và vì sao nó trở thành nền tảng đứng sau mọi ứng dụng AI hiện đại? Khi doanh…

Không ít người trong cộng đồng Learning Chain từng gặp một trải nghiệm quen thuộc: AI trả lời rất trôi chảy, lập luận nghe…

Có một câu chuyện mà cộng đồng Learning Chain hay nhắc với nhau khi nói về AI trong đời sống hằng ngày: AI đang…

Robotics không còn là tương lai xa vời mà đã trở thành một phần không thể thiếu trong cuộc sống hiện đại, từ các…