




Bot chiếm 1/3 traffic, Internet đã ‘chết’?
Con số cho thấy thuyết internet chết đang đúng dần theo từng ngày.
Table of Contents
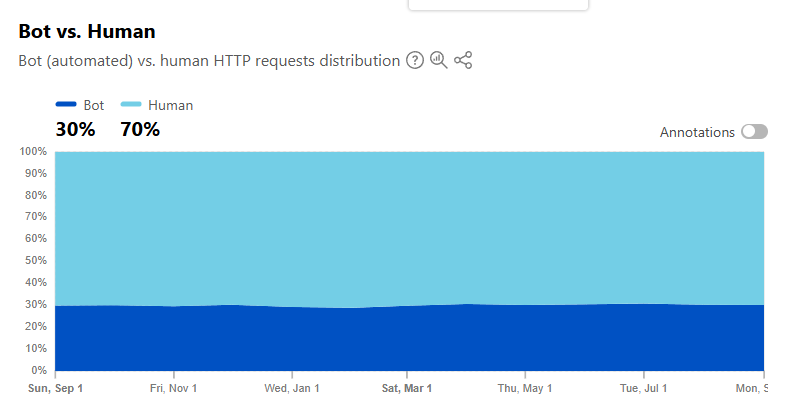
Thực trạng: bot chiếm gần 1/3 lưu lượng
Cloudflare công bố số liệu cho thấy gần một phần ba lưu lượng truy cập web hiện nay đến từ bot. Con số này không chỉ là thống kê kỹ thuật — nó phản ánh thay đổi sâu rộng trong cách nội dung và tương tác được tạo ra trên mạng. Ở cấp độ cơ bản, chúng ta đang chứng kiến sự chuyển hóa từ một Internet do con người chủ đạo sang một không gian trộn lẫn hành vi tự động và con người.
Tại phần sau, bài viết sẽ bóc tách hiện tượng theo ba lớp: (1) tại sao nó quan trọng, (2) bot là gì và phân loại, (3) cách hoạt động và hậu quả thực tế, cùng (4) các biện pháp khắc phục — kỹ thuật, chính sách và đạo đức.
Tại sao vấn đề bot lại quan trọng?
Why: Niềm tin và hiệu quả của hệ sinh thái số dựa trên giả định nhiều tương tác đến từ con người. Khi một lượng lớn tương tác bị thay thế bằng bot, độ tin cậy của dữ liệu, quảng cáo và thậm chí quyết định chính sách có thể bị méo mó.
Impact: Bot có thể làm méo giá trị quảng cáo (ad fraud), tăng chi phí vận hành nền tảng (moderation), làm sai lệch phân tích người dùng, và tạo môi trường dễ bị thao túng thông tin. Với AI tự hành, mức độ rủi ro tăng vì bot ngày càng giống hành vi con người, khiến việc phân biệt ngày một khó hơn.

Bot là gì và phân loại cơ bản
What: Bot là chương trình tự động thực hiện tác vụ trên mạng. Về tổng quan, ta có thể chia thành: (1) bot hợp pháp (search crawler, bot hỗ trợ dịch vụ), (2) bot có hại (scraper, spam, credential stuffing), và (3) bot ‘thế hệ mới’ chạy AI/agents tự động tương tác như con người.
Ví dụ cụ thể: Googlebot (bot hợp pháp), scraper thu thập giá, bot đăng bình luận rác (spam), và agent AI dùng để tạo hàng loạt tài khoản giả mạo để tương tác tự nhiên trên diễn đàn.
Cơ chế hoạt động của bot hiện đại
How: Bot truyền thống vận hành qua API, script, hoặc headless browser với các hành vi lặp lại (tải trang, gửi form). Bot hiện đại dùng mô hình ngôn ngữ để phân tích nội dung, mô phỏng hành vi người dùng, và thậm chí điều hướng tương tác đa bước (multi-step flows).
Kỹ thuật thường dùng: rotation IP, proxy, điều khiển thời gian hành vi giả (delay, click patterns), và tích hợp CAPTCHA solver. Những kỹ thuật này làm giảm hiệu quả các biện pháp phát hiện đơn giản.
Nhận diện bot: công cụ và hạn chế
What/How: Các nền tảng dùng nhiều lớp để phát hiện: phân tích hành vi (behavioral analytics), dấu vết mạng (fingerprinting), mô hình ML phát hiện bất thường, rate limiting, và kiểm tra tương tác (CAPTCHA).
Hạn chế: Khi bot có khả năng mô phỏng hành vi con người và vượt qua CAPTCHA, các phương pháp truyền thống mất hiệu lực. Thêm vào đó, việc tăng cường kiểm tra (ví dụ sinh trắc học) tạo ra vấn đề về quyền riêng tư và rủi ro về an toàn dữ liệu.
Tác động cụ thể tới nền tảng và người dùng
Why: Hiểu rõ tác động giúp nền tảng ưu tiên phản ứng phù hợp. Bot gây ảnh hưởng ở nhiều lớp: tài chính (fraud), chất lượng nội dung (thông tin sai lệch), và trải nghiệm người dùng (spam, overload).
So sánh các biện pháp kiểm soát bot
| Biện pháp | Ưu điểm | Nhược điểm |
|---|---|---|
| Biện pháp nhẹ (ít kiểm soát) | Giảm friction (ma sát cho người dùng), dễ tiếp cận | Dễ bị lạm dụng ad fraud, hiệu quả thấp với bot tinh vi, vẫn có spam |
| Xác minh mạnh (ví dụ: sinh trắc) | Hiệu quả cao trong việc giảm bot và spam | Đánh đổi quyền riêng tư, tạo rào cản gia nhập, nguy cơ lạm dụng dữ liệu |
Ví dụ thực tế: Ad fraud khiến nhà quảng cáo tiêu tốn chi phí trên lượt hiển thị ảo; nội dung do bot tạo tràn lan làm giảm tương tác thật dẫn tới vòng xoáy giảm doanh thu cho nền tảng.
Vai trò và xung đột lợi ích của các tập đoàn công nghệ
Why: Các công ty lớn vừa là tác nhân lan tỏa AI, vừa cung cấp giải pháp xác minh — tạo xung đột lợi ích. Ví dụ Sam Altman chỉ ra vấn đề bot trên Twitter/Reddit, đồng thời giới thiệu dự án sinh trắc ‘World’ để xác minh con người.
What: Mô hình kinh doanh đôi khi khởi nguồn từ việc tạo ra vấn đề (hoặc tận dụng hiện tượng) rồi bán giải pháp. Điều này đặt ra câu hỏi đạo đức và chính sách: liệu giải pháp có phải là cần thiết hay chỉ là cơ hội thương mại?
How (hệ quả): Nếu xác minh sinh trắc được triển khai rộng, nền tảng sẽ có công cụ mạnh để loại bot, nhưng đồng thời tập trung dữ liệu nhạy cảm vào vài tổ chức — rủi ro lộ lọt, kiểm soát danh tính, và loại trừ những người không muốn hoặc không thể tham gia.
Giải pháp kỹ thuật cân bằng hiệu quả và quyền riêng tư
What: Một bộ giải pháp hiệu quả thường kết hợp: (1) phát hiện hành vi nâng cao (ML), (2) xác minh đa tầng (email/phone, attestations, behavioral signals), và (3) biện pháp pháp lý/phối hợp ngành để giảm thị trường cho bot dịch vụ xấu.
How (triển khai): Thay vì ép người dùng quét võng mạc, nền tảng có thể ưu tiên attestations từ bên thứ ba, hệ thống trust scores, hoặc xác minh từng bước chỉ khi hành vi đáng ngờ. Kết hợp phân tích thời gian thực và cơ chế phản hồi từ người dùng sẽ vừa giảm bot vừa bảo vệ quyền riêng tư.
Ưu nhược: Các biện pháp nhẹ giảm friction nhưng kém hiệu quả với bot tinh vi; biện pháp nặng (sinh trắc) hiệu quả hơn nhưng tạo rào cản và nguy cơ lạm dụng dữ liệu.
Hướng đi chính sách và hợp tác ngành
Why: Vấn đề bot không thể giải quyết đơn phương bởi một nền tảng. Cần chuẩn mực chung, tiêu chuẩn chứng thực danh tính, và cơ chế chia sẻ thông tin để triệt nguồn cung dịch vụ bot.
What: Các đề xuất bao gồm luật chống ad fraud, quy định bảo vệ dữ liệu sinh trắc, và tiêu chuẩn mở cho attestations danh tính ít xâm phạm (decentralized attestations, privacy-preserving proofs).
How (thực tế): Chính phủ và ngành cần hợp tác để hạn chế kinh doanh dịch vụ bot, đồng thời tài trợ nghiên cứu cho phát hiện bot tinh vi và tiêu chuẩn bảo vệ quyền riêng tư trước công nghệ xác minh bắt buộc.
Kết luận
Cloudflare chỉ ra một thực tế đáng lo ngại nhưng không bất ngờ: bot đang chiếm lĩnh tầm ảnh hưởng trên Internet. Nhận diện đúng bản chất — Why/What/How — giúp chúng ta chọn giải pháp cân bằng giữa hiệu quả chống bot và bảo vệ quyền riêng tư người dùng.
Kết luận ngắn: không có phương án đơn lẻ nào là đủ. Mô hình hiệu quả là kết hợp kỹ thuật phát hiện tinh vi, xác minh đa tầng có chọn lọc, tiêu chuẩn ngành, và khung pháp lý bảo vệ dữ liệu. Người dùng, nhà phát triển và nhà lập pháp đều phải tham gia để tránh kịch bản ‘Internet chết’ — nơi tương tác nhân tạo vượt trội so với tương tác thật.
Cảm ơn bạn đọc!
FAQ – Câu hỏi thường gặp
Bot thực sự chiếm bao nhiêu phần trăm lưu lượng?
Cloudflare báo gần 1/3 trong dữ liệu của họ, nhưng con số thực có thể khác giữa các nền tảng. Một số nghiên cứu trước đây ước tính tỉ lệ bot (tính theo request) dao động từ 20% đến >50% tùy phương pháp đo. Quan trọng là xu hướng tăng và chất lượng bot (khả năng giả dạng) chứ không chỉ phần trăm.
Xác minh sinh trắc học có phải là giải pháp an toàn?
Sinh trắc học có thể rất hiệu quả trong việc chặn bot, nhưng nó đi kèm rủi ro lớn về quyền riêng tư và tập trung dữ liệu nhạy cảm. Giải pháp bền vững cần cân bằng: dùng sinh trắc trong tình huống nguy cấp, kết hợp với phương thức attestations và kỹ thuật bảo vệ dữ liệu như privacy-preserving proofs.
Người dùng bình thường có thể làm gì để bảo vệ chính mình?
Người dùng nên: (1) kích hoạt xác thực hai bước ở nơi hỗ trợ, (2) cẩn trọng với đường link và yêu cầu đăng nhập lạ, (3) ưu tiên nền tảng minh bạch về chính sách xác minh và dữ liệu, và (4) tiếp tục phản hồi khi gặp nội dung khả nghi để nền tảng cải thiện bộ lọc.

Tokenomics là gì? Hướng dẫn A-Z cho người mới
Khi bước chân vào thế giới đầu tư tiền điện tử, bạn sẽ đối mặt với hàng nghìn dự án khác nhau. Để tìm thấy những viên ngọc quý và tránh xa rủi ro, việc trang bị kiến thức về Tokenomics là điều tối quan trọng. Tokenomics không chỉ là một thuật ngữ phức tạp...
Morgan Stanley đưa crypto lên E*Trade, Liệu thay đổi lớn?
Table of Contents Bối cảnh: Morgan Stanley bước vào thị trường crypto bán lẻ Tại sao động thái này quan trọng? (Why) Nó là gì: Tóm tắt hợp tác với Zerohash (What) Tác động ban đầu đến ngành (How – phản ứng thị trường) Chi tiết chương trình giao dịch crypto cho E*Trade Tại sao...

Bitcoin vào 401(k), Người lao động có được lợi?
Table of Contents Mở đầu — Bối cảnh và ý nghĩa Tại sao chuyện này quan trọng? (Why) Executive Order 14330 là gì? (What) Ảnh hưởng trực tiếp ban đầu (How) Diễn biến pháp lý và vận động hành lang Diễn biến gần đây: thư gửi SEC và DOL (What) Mục tiêu chính sách đằng...

Whales bán tháo ETH, Nguy cơ thủng $4,000?
Table of Contents Mở đầu Tại sao chuyện này quan trọng? (Why) ETH là gì và các thành phần liên quan (What) Diễn biến và cách đọc dữ liệu (How) Top Investors Dump ETH, Raising Short-Term Breakdown Fears Tại sao hành động của top holders lại là tín hiệu quan trọng? (Why) Dữ liệu hiện...

SEC nới quy tắc crypto, Liệu đổi vận cho thị trường?
Table of Contents Mở đầu: ‘Innovation exemption’ — một bước ngoặt của SEC Tại sao đề xuất ‘innovation exemption’ lại quan trọng? Định nghĩa và thành phần của ‘innovation exemption’ Cơ chế vận hành và ví dụ minh họa SEC thay đổi giám sát trong bối cảnh chính sách mới Áp lực chính trị và...




